Claude 3.5 Sonnet vs OpenAI o1: A Comprehensive Comparison
The market is more crowded than ever, with models offering a dizzying array of capabilities. If you’re building tools for coding, tackling complex reasoning problems, or optimizing workflows, two advanced models stand out: Claude 3.5 Sonnet and OpenAI o1.

In this guide, we will help you understand which model suits your needs best. We’ll break down their performance, pricing, coding abilities, and special features to give you a clear picture of what each model brings to the table. After all, the right choice can make a significant difference in both your productivity and budget.
Why Compare Claude 3.5 Sonnet and OpenAI o1?
Choosing the right model can mean the difference between saving hours on coding tasks or struggling with incomplete solutions. It can also impact your budget, especially for long-term or high-volume use.
Quick Compare
| Claude 3.5 Sonnet | OpenAI o1 | |
|---|---|---|
| Cost | $3.00 per million input tokens $15.00 per million output tokens | $15.00 per million input tokens $60.00 per million output tokens |
| Average Response Time | ~18.3s/request Fast responses, ideal for real-time tasks. | ~39.4s/request Slower, focuses on detailed reasoning. |
| Output Token Limit | 4,096 tokens | 32,768 tokens |
| Context Window | 200,000 tokens | 128,000 tokens |
| Knowledge Cutoff | April 2024 | October 2023 |
| Recommended For | Good for everyday coding, debugging and quick retrieval. | Good for complex reasoning, long-context problems, and the need for nuanced explanations. |
Core Differences Between Claude 3.5 Sonnet and o1
OpenAI o1 is built for complex reasoning and problem-solving. Its deep, thoughtful responses make it perfect for developers working on intricate issues or requiring detailed explanations. o1 excels in tasks that demand precision and depth, such as advanced mathematics or scientific analysis.
In contrast, Claude 3.5 Sonnet focuses on speed and efficiency. It delivers quick responses, making it ideal for high-volume tasks, such as rapidly generating code or handling routine queries. With its cost-effective pricing, it’s a strong choice for users who prioritize productivity over deep reasoning.
Let’s dive deeper into the performance, cost and speed.
1. Performance: Coding, Debugging, and Advanced Reasoning
In general, Claude’s strength lies in rapid generation and its simplicity. OpenAI’s o1 is better for deep reasoning and debugging.
| Claude 3.5 Sonnet | OpenAI o1 | |
|---|---|---|
| Coding | ✅ Excels in speed and reliability for generating boilerplate code, unit tests, and handling repetitive coding tasks. | ✅ Excels at solving intricate coding problems and handling advanced algorithms.Debugging complex React state management issues and getting suggestions for legacy code refactoring. |
| Debugging | ✅ Fast at identifying common coding errors and providing quick fixes. | ✅ Delivers analyses of multi-step errors, valuable for debugging complex workflows. |
| Advanced Reasoning | ✅ Handles general reasoning tasks effectively but focuses more on productivity and speed. | ✅ Excels in deep reasoning and problem-solving, good for scientific research and advanced mathematics. |
| Example Use Cases | 1. Generating setup files for 50+ APIs in short time. 2. Detecting overlooked security vulnerabilities and debugging nested functions. | 1. Debugging React state management issues and legacy code refactoring. 2. Using o1's to explain algorithmic issues for debugging. |
2. Cost Efficiency
Claude 3.5 Sonnet is 4x cheaper than OpenAI o1. It’s ideal for budget-conscious users who need reliable performance for everyday coding tasks, whereas o1 is best for users tackling high-value projects where advanced reasoning and context retention justify the cost.
| Claude 3.5 Sonnet | OpenAI o1 | |
|---|---|---|
| Input Cost | $3 per million tokens | $15 per million tokens |
| Output Cost | $15 per million tokens | $60 per million tokens |
| Highlight | More budget-friendly and cost-effective | More expensive, but offers advanced reasoning and in-depth analysis |
Using Claude? Save up to 70% of API costs for free ⚡️
Helicone users cache response, monitor usage and costs to save on API costs.
3. Context Window and Speed
Claude 3.5 Sonnet can handle about 150% more tokens compared to OpenAI o1, giving it an edge for tasks requiring extensive context retention. The size of a context window is essential in determining how well AI models manage large inputs or extended conversations.
| Claude 3.5 Sonnet | OpenAI o1 | |
|---|---|---|
| Context Window | Supports up to 200,000 tokens | Handles up to 128,000 tokens |
| Token Throughput | 74.87 tokens/second | 92.94 tokens/second |
| Average Latency | 18.3 seconds per request | 39.4 seconds per request |
| Best For | Handling large codebases, lengthy documents or high-volume tasks and real-time applications. | Multistep reasoning and tackling intricate problems that require breakdowns. |
What’s new in the upgraded Claude 3.5 Sonnet - October 2024
On October 22, 2024, Anthropic released a new version of Claude 3.5 Sonnet, improving its SWE-bench Verified benchmark score from 33.4% to 49.0%, surpassing all publicly available models including OpenAI's o1-preview at 41.0%.
The upgraded model shows wide-ranging improvements across various industry benchmarks, particularly in coding and tool use tasks. Anthropic also introduced Computer Use capability that allows Claude 3.5 Sonnet to perform tasks by interacting with user interfaces (UI), such as generating keystrokes and mouse clicks.
Model Benchmarks
Benchmarks help measure speed, accuracy, and efficiency between models. Let's look at real-world benchmarks to understand how o1 and Claude 3.5 Sonnet performs in practical applications.
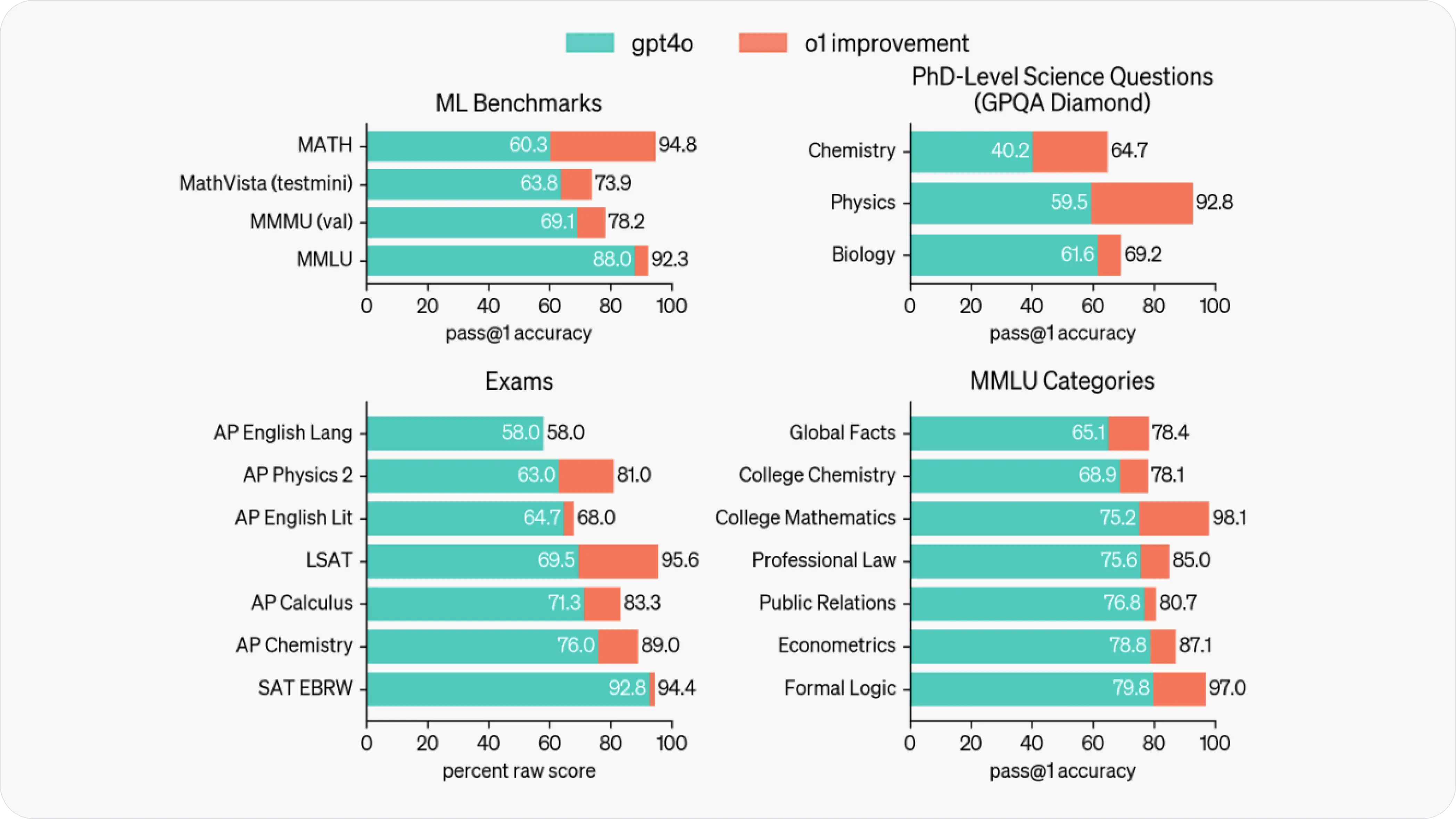
| Benchmark | OpenAI o1 | Claude 3.5 Sonnet |
|---|---|---|
| MMLU General Knowledge and Reasoning | 92.3% OpenAI | 89.3% (0-shot CoT) Paper |
| MMMU A wide ranging multi-discipline and multimodal benchmark | 78.2% OpenAI | 68.3% (0-shot CoT) Paper |
| HellaSwag Measures common sense inference and reasoning | Benchmark not available | Benchmark not available |
| GSM8K Grade-school math problems benchmark | Benchmark not available | 96.4% (0-shot CoT) Paper |
| HumanEval Evaluates Python coding tasks | 92.4% (shared by o1-preview and o1-mini) | 93.7% Anthropic |
| MATH Assesses mathematical problem-solving abilities across 7 difficulty levels | 94.8% OpenAI | 71.1% (0-shot CoT) Paper |
💡 Keep in mind that o1 uses more compute to achieve its advanced reasoning capabilities, which helps it outperform Claude 3.5 Sonnet in many benchmarks.
Comparing Claude 3.5 Sonnet and o1 on Coding Tasks
We will now look at some examples of how Claude 3.5 Sonnet and o1 perform on generating simple functions, debugging, and writing unit tests.

Example 1: Generating a Simple Function
Prompt: Write a Python function that takes a list of integers and returns the sum of all even numbers in the list. The function should handle empty lists and lists containing only one element.
--> Try it with Claude 3.5 Sonnet
| Model | Observation |
|---|---|
| Claude 3.5 Sonnet | Used a simple loop to iterate through the list, with clear variable names and minimal comments. Clean and straightforward solution. |
| OpenAI o1 | Addressed all the requirements and handled edge cases well (i.e.empty lists and lists with one element). The code was well-structured. |
Which model performed better?
Claude 3.5 Sonnet provided a simpler and more elegant solution, while OpenAI o1's approach was more thorough with edge case handling.
Example 2: Debugging Code
Prompt: Debug this JavaScript function to remove all vowels from a string.
function removeVowels(str) {
return str.replace(/[aeiou]/gi, ");
}
→ Try the prompt with GPT-4o (as o1 isn't supported yet)
| Model | Observation |
|---|---|
| Claude 3.5 Sonnet | Clearly pinpointed the mistake and provided a straightforward and simple-to-understand solution. |
| OpenAI o1 | Quickly identified the issue and offered an efficient solution that addresses the problem directly without adding unnecessary complexity. |
Which model performed better?
Both models showed strengths in debugging. OpenAI o1 is direct, while Claude 3.5 Sonnet provided a more user-friendly solution. This aligns with reports that o1 excels in complex problem-solving while Claude is preferred for simpler tasks.
Example 3: Writing Unit Tests
Prompt: Develop a set of unit tests for a function that takes a list of strings as input and returns a new list containing only the strings that are palindromes. The function should handle empty lists and lists containing only one element.
| Model | Observation |
|---|---|
| Claude 3.5 Sonnet | Produced a comprehensive set of unit tests covering all edge cases such as empty lists and single-element lists. |
| OpenAI o1 | o1 also generated a solid set of unit tests, but lacked depth in addressing critical edge cases such as lists with multiple palindrome and non-palindrome strings. |
Which model performed better?
This test indicates that Claude 3.5 Sonnet is more efficient in generating thorough unit tests, while o1's tests are functional but could be improved.
How to build an AI app with o1 or Claude 3.5 Sonnet? 💡
Visit Helicone's docs and copy the code snippet to integrate with usage and cost tracking.
Choosing the Right AI Model
To select your ideal model, consider how their unique features help you meet your requirements.
- For applications that require desktop automation, pick Claude for its computer use feature that allows you to interact with computers.
- For deep reasoning and more complex problem-solving, OpenAI o1 makes a better choice.
- For budget-conscious users who don't need the 5-10% improvement that comes with o1, Claude 3.5 Sonnet is a better choice as it is 4x cheaper.
- For users who need to interpret charts and graphs, Claude 3.5 Sonnet is better as it scores
90.8%on the Chart Q&A benchmark compared to GPT-4o's85.7%(o1's data is currently not public). - For real-time applications, Claude 3.5 Sonnet is faster, with an average latency of
18.3sper request compared to o1's39.4s. - For users looking for the better coding experience, both models are good choices. But if you're looking for a more cost-effective choice for everyday coding tasks, particularly when integrated with tools like GitHub Copilot, Claude 3.5 Sonnet can be better.
Is OpenAI o1's Pro mode worth it?
While o1 Pro mode showed impressive results, some users found the performance gap between o1 Pro and Claude 3.5 Sonnet narrower than one might expect, since Claude 3.5 Sonnet can already achieve 90-95% accuracy in most applications, with significantly faster response times.
How do you access o1 Pro mode?
OpenAI's o1 Pro is the most advanced version of the o1 model available through the OpenAI API. Developers must subscribe to the ChatGPT Pro plan, which costs $200 per month.
Bottom Line
For most users, especially those working on practical coding tasks or needing fast, reliable solutions, Claude Sonnet 3.5 offers better value for money. However, if your work requires specialized capabilities like advanced vision or deep scientific analysis, and budget isn’t a concern, o1 Pro would be the better option.
Ultimately, the decision hinges on whether you prioritize cutting-edge features and accuracy or a more cost-effective, practical AI solution.
Other related comparisons
-
O1 (and ChatGPT Pro) — here's everything you need to know
-
Is Llama 3.3 better than Claude-Sonnet-3.5 or GPT-4?
-
Google's Gemini-Exp-1206 is Outperforming O1 and GPT-4o
Questions or feedback?
Are the information out of date? Please raise an issue and we'd love to hear your insights!