Llama 3.3 just dropped — is it better than GPT-4 or Claude-Sonnet-3.5?
Meta just released their newest AI model Llama 3.3. This 70-billion parameter model caught the attention of the open-source community, showing impressive performance, cost efficiency, and multilingual support while having only ~17% of Llama 3.1 405B's parameters.

But is it truly better than the top models in the market? Let’s take a look at how Llama 3.3 70B Instruct compares with previous models and why it's a big deal.
Comparing Llama 3.3 with Llama 3.1
Improved speed
Llama 3.3 70B is a high-performance replacement for Llama 3.1 70B. Independent benchmarks indicate that Llama 3.3 70B achieves an inference speed of 276 tokens per second on Groq hardware, surpassing Llama 3.1 70B by 25 tokens per second. This makes it a viable option for real-time applications where latency is critical.
Similar performance, fewer parameters
Despite its smaller size, Meta claimed that Llama 3.3 has powerful performance comparable to the much larger Llama 3.1 405B model. With significantly lower computational overhead, developers can deploy it using mid-tier GPUs or run the model locally on their consumer-grade laptops.
Same multilingual support
Like its predecessor Llama 3.1, Llama 3.3 also supports 8 languages, including English, Germain, French, Italian, Portuguese, Hindi, Spanish, and Thai. The model is versatile for developers who are targeting global audiences. On the Multilingual MGSM (0-shot) test, it scored 91.1, which is similar to its predecessor Llama 3.1 70B (91.6) and close to more advanced models like Claude 3.5 Sonnet (92.8). More on this later.
More cost-effective
Llama 3.3 70B has a significant advantage over its costs:
$0.10per million input tokens, compared to $1.00 for Llama 3.1 405B, and$0.40per million output tokens, compared to $1.80 for Llama 3.1 405B
In an AI conversation agent example by Databricks, using Llama 3.3 70B is 88% more cost-effective to deploy than Llama 3.1 405B.
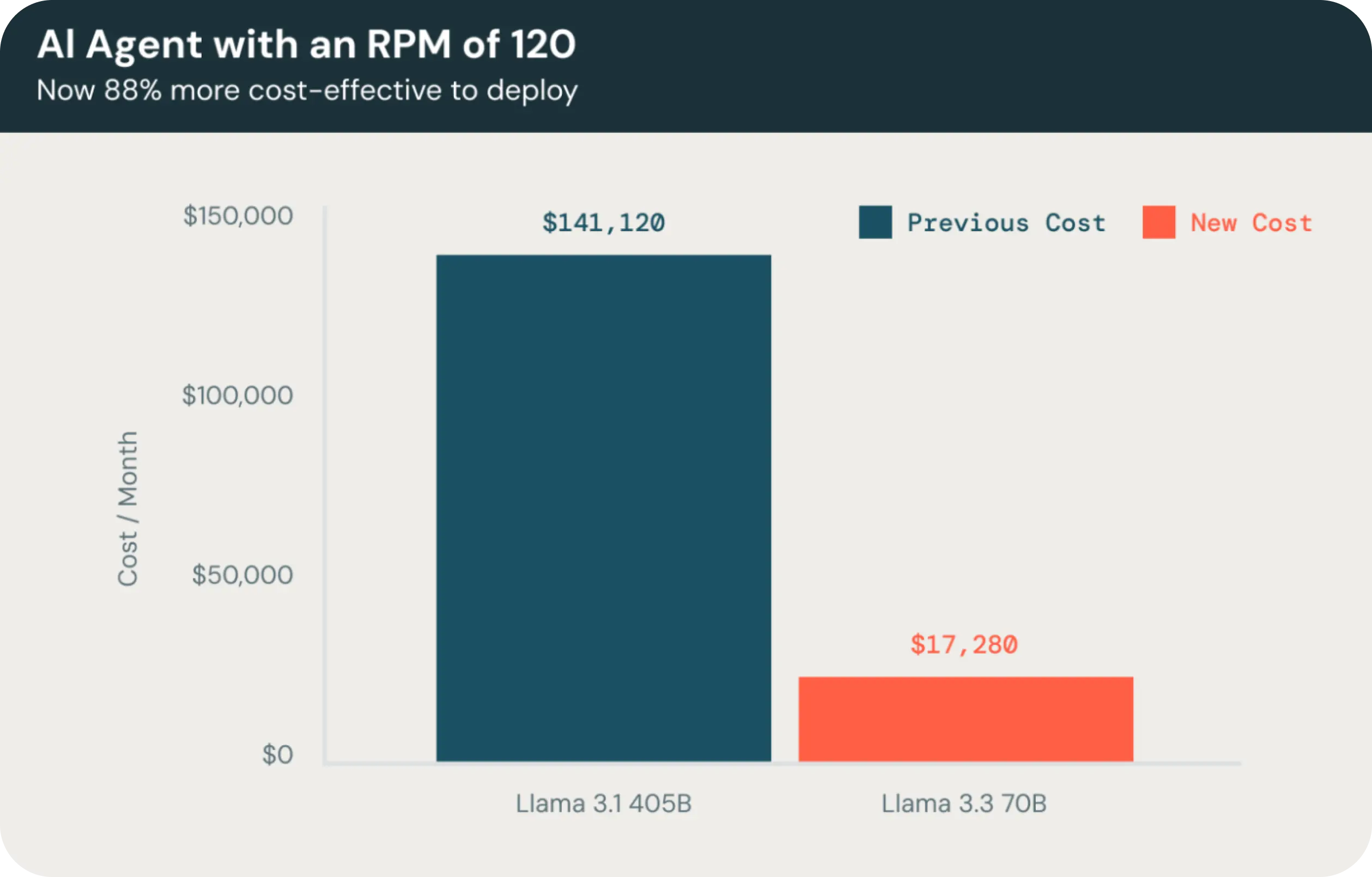
Cut Llama 3 API costs by up to 70% ⚡️
Use Helicone to cache responses, optimize prompts, and more.
Extended context window
Llama 3.3 70B supports a large context window of 128,000 tokens like Llama 3.1 405B. This extensive context handling allows both models to process large volumes of data and maintain contextual awareness in conversations.
Performance Benchmarks
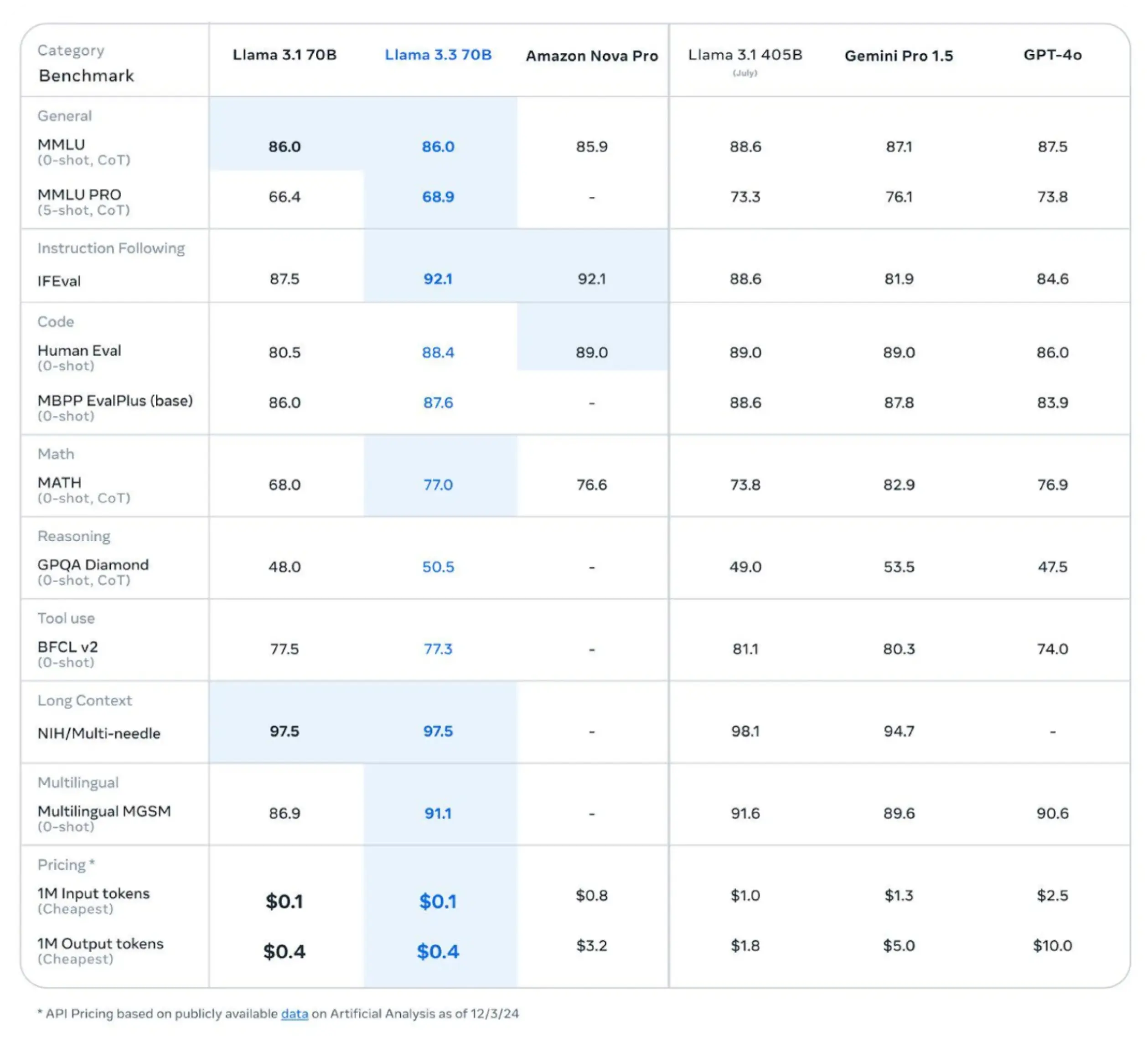
Llama 3.3 has impressive results across code, math, and multilingual benchmarks. Highlights include:
- A high score of 92.1 in IFEval (instruction following).
- 89.0 in HumanEval and 88.6 in MBPP EvalPlus (code).
- Excels in the Multilingual MGSM benchmark with a score of 91.6.
In some evaluations, Llama 3.3 70B even outperforms established models like Google's Gemini 1.5 Pro and OpenAI's GPT-4 on key benchmarks, including MMLU (Massive Multitask Language Understanding).
Is Llama 3.3 better than GPT-4 or Claude-Sonnet-3.5?
At a glance, Llama 3.3’s open-source nature makes it more customizable and accessible for developers. It also has lower operational costs which appeals to small and mid-sized teams.
| Llama 3.3 | GPT-4 | Claude 3 | |
|---|---|---|---|
| Parameters | 70B | Unknown (estimated large) | ~100B |
| Cost-effectiveness | High (low token cost) 🏆 | Moderate | Moderate |
| Open Source | Yes | No | No |
| Multilingual Support | Moderate | Extensive 🏆 | Moderate |
| Fine-Tuning | Easy and flexible 🏆 | Limited (API-based) | Limited (API-based) |
| Ideal Use Cases | Cost-sensitive, domain-specific | Broad tasks | General NLP tasks |
How to access Llama 3.3 70B?
Llama 3.3 70B is available through Meta's official Llama site, Hugging Face, Ollama, Fireworks AI, and other AI inferencing platforms.
Use Cases of Llama 3.3
Llama 3.3 70B is versatile and can be used for various tasks, including:
- Chatbots and virtual assistants: Faster model speed and better accuracy helps to improve user experience, especially in customer service applications.
- Localization and translation services
- Content creation and summarization: developers report faster output generation for marketing copy, technical writing, and creative projects.
- Code generation and debugging
- Synthetic data generation
Limitations of Llama 3.3
- License restrictions: The license prohibits using any part of the Llama models, including response outputs, to train other AI models.
- Limited modalities: Llama 3.3 70B is a text-only model, lacking capabilities in other modalities such as image or audio processing
- Knowledge cutoff: The model's knowledge is limited to information up to December 2023, making it potentially outdated for current events or recent developments79.
Conclusion
Llama 3.3 is a major advancement in open-sourced large language models. The increasing efficiency improvements are allowing developers to access more affordable and incredibly faster models, and more incredibly powerful models that one can run directly on their own device, making it more accessible to the open-source community.
Interested to learn about other models?
-
O1 and ChatGPT Pro — here's everything you need to know
-
GPT-5 — Release date, features & what to expect
FAQ
How to finetune Llama 3.3?
Fine-tuning Llama models can be done in two main ways:
- Full parameter fine-tuning by adjusting all model parameters. Best performance, but very time-consuming and GPU-intensive.
- Parameter efficient fine-tuning (PEFT) using either LoRA or QLoRA.
Meta’s official fine-tuning guide recommendeds starting with LoRA fine-tuning. If resources are extremely limited, use QLoRA. Then evaluate model performance after fine-tuning, and only consider full parameter fine-tuning if the results are not satisfactory.
What data was Llama 3.3 70B trained on?
Llama 3.3 70B was pretrained on 15 trillion tokens from public sources, 7 times larger than Llama 2’s dataset. The training data includes:
- New addition of publicly available online data
- 25+ million synthetically-generated examples for fine-tuning
- 4x more code data than Llama 2
- 5%+ non-English data across 30+ languages
What is the knowledge cutoff of Llama 3.3 70B?
Llama 3.3 70B has a knowledge cutoff of December 2023.
Questions or feedback?
Are the information out of date? Please raise an issue and we’d love to hear your insights!